- Published on
DSPy - Gemma Sprint
- Authors

- Name
- Martin Andrews
- @_mdda_
Gemma model try-out with DSPy
Gemma Sprint (March-2024)
As part of my participation in Google’s GDE program (I have been a Google Developer Expert for AI/ML since 2017), I am given the chance to take part in various “ML Sprints” - in which we are expected to propose interesting tasks to do (using a specific technology), and then complete them. The result could be presentation materials, videos, code contributions, etc.
My idea for the Gemma sprint (which was launched when Google announced their open-sourcing of the Gemma 2B and 7B models) was to look at whether it could be used within DSPy - since the framework held the promise of being able to optimise prompts to suit whichever LLM was used as the backbone.
However, while Gemini appeared to work well for DSPy, Gemma was a surprising non-starter, as explained below.
Basic DSPy LLM interrogation
DSPy tends to hide a lot of the mechanics of its interactions with the backbone LLM so that it can abstract away the specifics. However, the problems that I encountered with Gemma can be traced back to how DSPy wants to interact with an LLM : Specifically, it wants the LLM to complete the template that has already been partially filled out by DSPy.
Here’s an example, where the black text is from DSPy to the LLM, and the correct continuation from Gemini 1.0 Pro is the single highlighted answer:
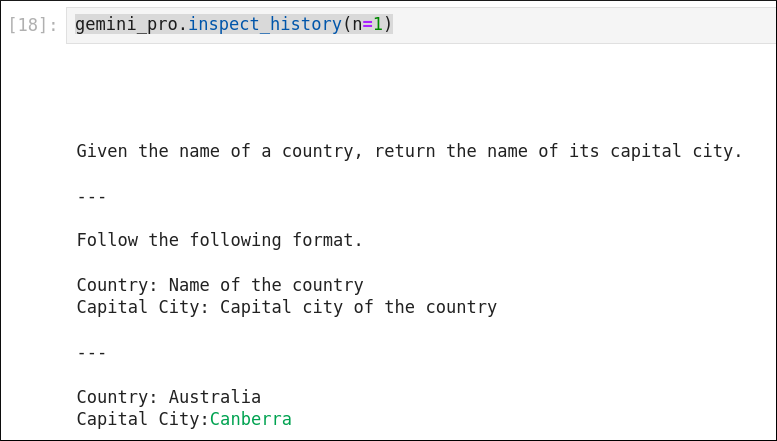
Using Gemma locally
Ollama is my go-to solution for running models locally (or even on a cloud instance on GCP), since it is super simple to set up, and just works .
# Update OLLaMa to latest version (>0.1.26 is required)
## AND YES : I TOO HATE IT WHEN INSTALLATION WANTS YOU TO DO THIS
curl -fsSL https://ollama.com/install.sh | sh
## IT'S A REALLY BAD IDEA. REALLY.
# https://ollama.com/library/gemma:7b-instruct
ollama pull 'gemma:7b-instruct'
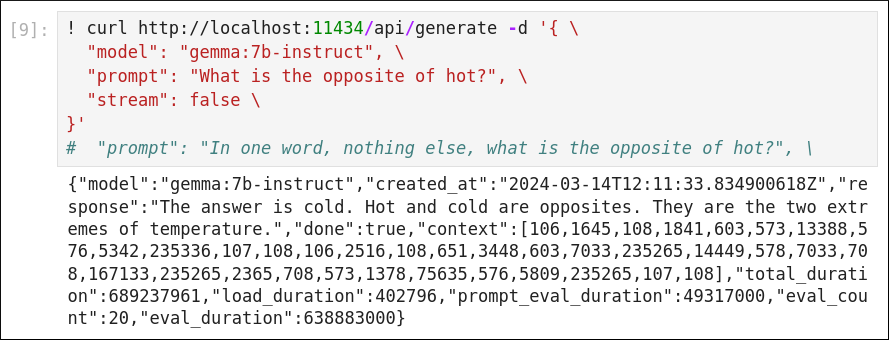
Gemma 1.0 : Too helpful!
Just looking at the basic response that Gemma 1.0 gives to a curl call shows its likely failure mode when used via DSPy:
And, to prove the point, here is how it completes the DSPy template (the problem being that the response in green adds additional text, and repeats part of the template, which is extremely confusing):
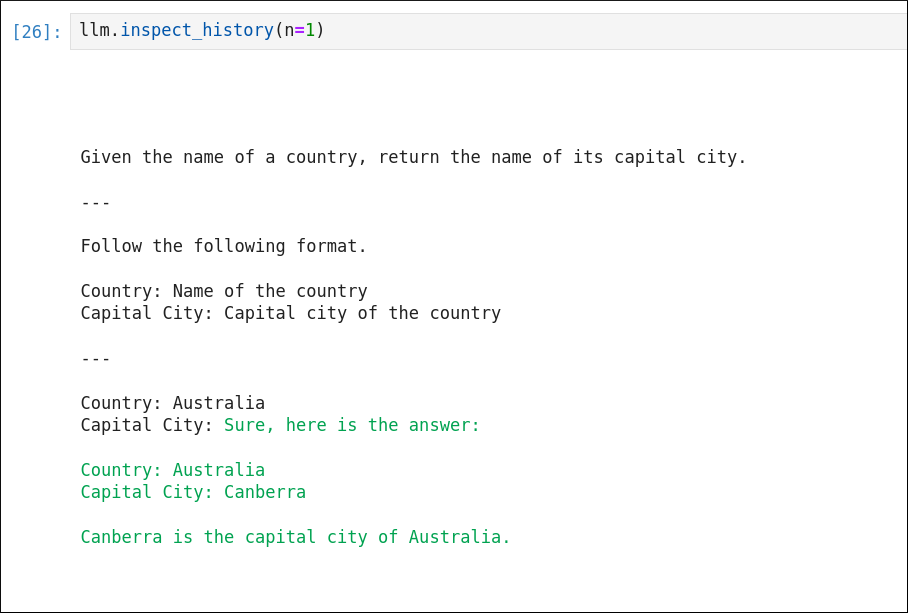
This is a fatal flaw which is tricky to fix with prompting, since DSPy has a fairly rigid structure of how the prompt pieces are sequenced. Moreover, since the output lacks consistency, even post-processing the gemma-1.0 response would be very fragile
Gemma 1.1 : Almost there!
Updated versions of the Gemma instruct models were released on the 5th April 2024 (with little fanfare from Google). This appears to have been a pretty decent update - with the model responses looking far more ‘mature’ than the original fine-tuning (most people had pegged the gemmma-instruct SFTs as being half-hearted, considering that the base models seemed good overall).
A simple repeat of the curl query shows that the model is still pretty eager to help, but overshares less:
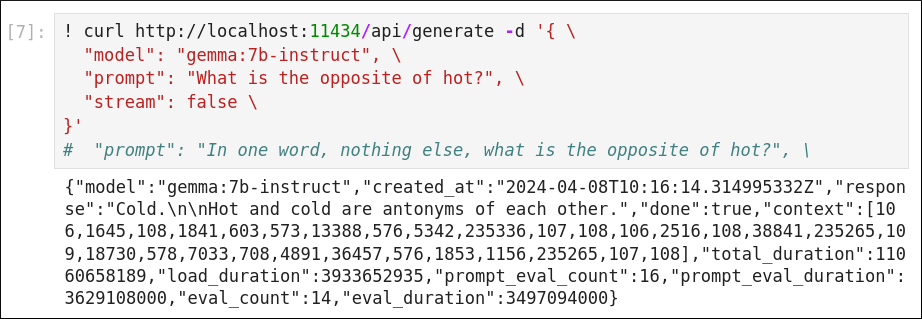
and this is reflected in the almost-usable completion of the DSPy template:
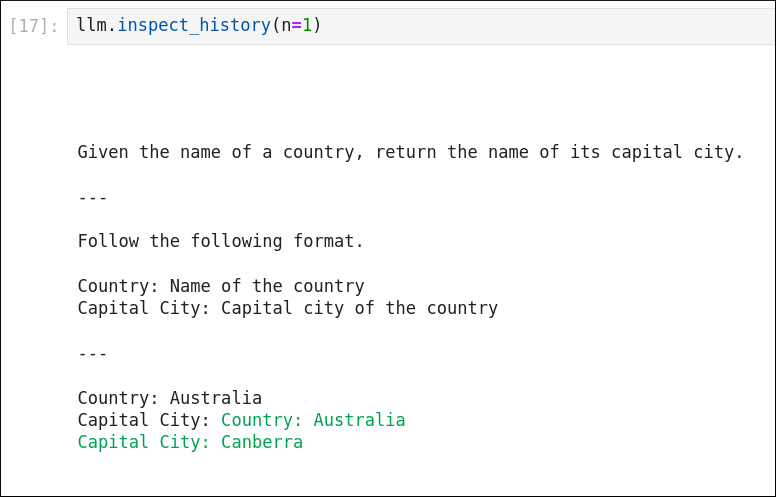
However, it’s still not a direct enough completion to make DSPy happy out of the box…
Tidying up the Gemma 1.1 output
The following code could be a starting point for cleaning up the gemma 1.1 output, since it does appear to want to follow the template, just not respect the fact that some of the template already exists :
import re
def extract_final_answer(example, completion_list):
"""Extracts the answer from the LM raw prediction using the template structure.
Args:
example (Union[Example, dict[str, Any]]):
Contains the input variables that raw_pred was completed on.
completion_list (list[str]): List of LM generated strings.
Returns:
list[str]: List of extracted answers.
"""
# Extract the answer based on the prefix of the output field
completions = []
for k,v in example.signature.output_fields.items():
prefix = v.json_schema_extra["prefix"]
#print(f"Extracting for {prefix=} in ", completion_list)
for completion in completion_list:
for l in completion.split("\n"):
if l.startswith(prefix):
completions.append(
re.sub(rf"{prefix}\s*", "", l, flags=re.IGNORECASE).strip()
)
return completions # Really would like a dict here...
extract_final_answer(predictor, prediction.completions.capital_city)
# == ['Canberra']

Conclusions
My guess is that gemma could be a workable backbone LLM for DSPy given:
- code additions to DSPy itself (default disabled under flag(s)); or
- a fairly simple additional fine-tune applied to
gemma-1.1-7b-itso that it might recognise that parts of the template have already been provide (so that it won’t reproduce the elements of the required answer that have already been supplied).
As always : So many things to do, so little time!