- Published on
Long Context Transformers
- Authors

- Name
- Martin Andrews
- @_mdda_
Presentation Link
The fifty-first MeetUp of the Machine Learning Singapore Group, was titled : “In-Context Learning tricks: Longer Contexts, Better Models & Cheap Summarization”. We had a good turn-out, with over 350 sign-ups, and the event was packed with interesting and diverse content!
My talk was titled “Long Context”, and was divided into the following sections:
- Transformer refresher (to ensure the audience all knew about how attention mechanisms were crucial to transfomer performance, and their issues)
- Benefits of Long Context
- Achieving Long Contexts
- Ring Attention
- Rumoured to be behind Gemini 1.5’s 1 million token context window
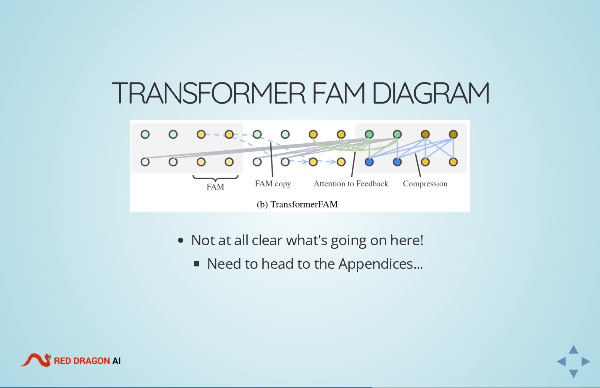
- Infini-Attention / Transformer FAM
- Two April-2024 papers from Google - an interesting contrast!
- Ring Attention
In his talk “Creating a Cheap, Fast Summarization & Note Taking System”, Sam Witteveen talked about how to make good use of long context windows, highlighting the strength/cost ratio of Anthropic’s Haiku model. He also showed a concrete example of how a series of prompts that leveraged long contexts could be made to work together effectively.
We also were pleased to have two other talks:
“RWKV and Next Gen LLMs”
- Eugene Cheah
“Learnings from Pre-training an LLM Encoder for South East Asian languages from Scratch”
- Srinivasan Nandakumar
Many thanks to the Google team, who not only allowed us to use Google’s Developer Space, but were also kind enough to provide Pizza for the attendees!
The slides for my talk, which contain links to all of the reference materials and sources, are here :

If there are any questions about the presentation please ask below, or contact me using the details given on the slides themselves.