- Published on
Gemini 1.5 One Million Sprint
- Authors

- Name
- Martin Andrews
- @_mdda_
Gemini 1.5 (1 million tokens) try-out
Gemini 1.5 Sprint
As part of my participation in Google’s GDE program (I have been a Google Developer Expert for AI/ML since 2017), I am given the chance to take part in various “ML Sprints” - in which we are expected to propose interesting tasks to do (using a specific technology), and then complete them. The result could be presentation materials, videos, code contributions, etc.
My idea for the Gemini 1.5 sprint (where we got early access to the large-context Gemini model within AI Studio) was to look at ways in which it could replace/augment RAG. It turned out that this idea didn’t pan out as expected, but there were several interesting ideas that beat expectations.
Apart from the following, I was able to demonstrate the potential of Gemini 1.5 to developers in Singapore at both MLSG and AI Wednesdays events.
One misfire, and two wins
Improve a RAG system
My original ‘pitch’ was to use the large context model to accurately calibrate a RAG system over many documents.
One key problem of doing RAG calibration is that while it may be known that a particular fact is present in a chunk of text, it is not normally known that it is definitely not present in all other chunks. So, when training contrastively on a ‘find the useful chunk’ task, it is easy to be training positive examples as negatives - which undermines then whole technique.
By being able to accurately identify positives and negatives over large numbers of chunks, a large context model should be able to create better training data for the RAG system.
(NB: in real-life situations, fitting all of the documents within even a 1 million token context window is unrealistic).
Sadly however, this idea didn’t pan out:
- Since we only got access to AI studio (rather than an API version), it would be impractical to generate any significant dataset (even though it would be super-clean)
- The actual processing speed of Gemini 1.5 (when given a large context) is of the order of 40-100secs. In retrospect, this isn’t unreasonable, but it certainly also limits the idea of replacing standard RAG systems outright
- Other techniques for improving RAG (such as RAPTOR) are also showing promise - and these may alleviate the need for pin-point accurate training data
Reason over textual documents
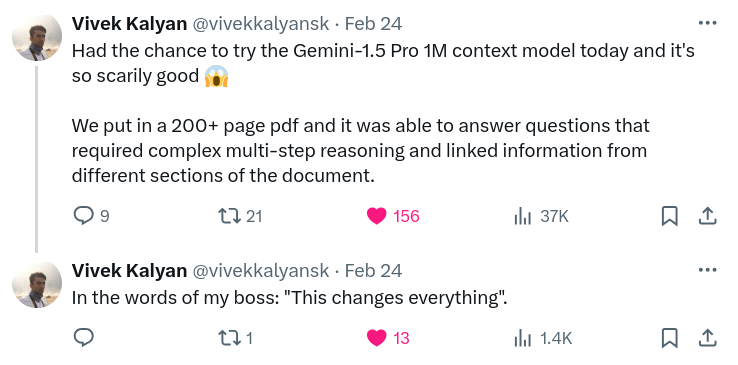
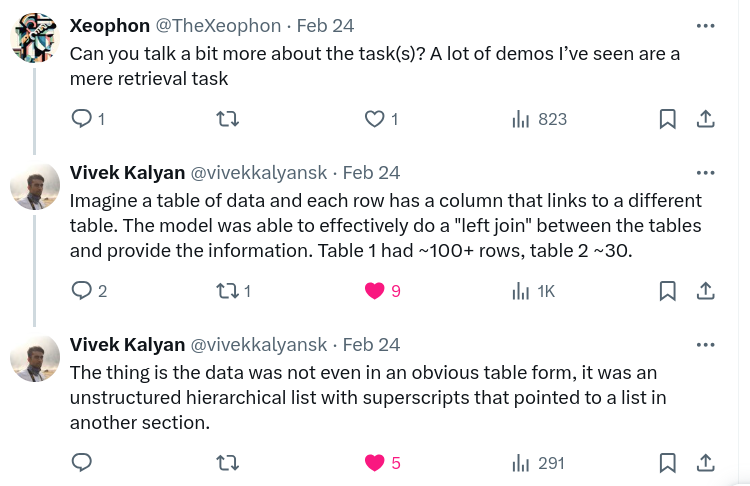
This use-case is based on a (private) requirement of a Singaporean company that I do consulting for - so I can’t get into the actual details. Suffice to say : Gemini’s handling of PDFs, and reasoning within the large context, may cause some rethinking of existing business processes.
So as to give a little more information about what Gemini can do that is so impressive : An equivalent task can be framed as (for instance) examining a PDF from arXiv, and returning the list of papers cited within a given table.
This was tweeted out by a member of their AI team :
Reason over codebase
Another use-case the Gemini Pro 1.5 (1 million context) excelled at was the generation of code, when reasoning over a large codebase.
I wanted to build a number of demonstrations of the usage of a very new framework (DSPy). Because this was so new, there was no chance that the latest changes would be within the Gemini training data - so the only way to get Gemini to create relevant code would be to allow it to see the contents of the Repo itself.
So that this could be done in a controlled way, I created a folder-to-textfile converter that took the DSPy repo contents (restricted to .py and .md files) and built a nicely organised text file from it.
From there, prompting for the creation of the required code was straightforward (returning 933,975 bytes, which turned into 246,297 Gemini tokens), and Gemini was able to give me complete, detailed working code one-shot. It was extremely impressive. The slides in my final presentation outlined how it all came together.
To enable others to do a similar trick, here is the code of my folder-to-textfile converter - which builds on a similar idea from Eric Hartford, but formulated in a more general way.
import os, sys
import requests, zipfile
import io
import ast
def is_desired_file(file_path):
"""Check if the file is a Python, JavaScript, TypeScript, Svelte, or Rust file."""
is_code = file_path.endswith(".py") or file_path.endswith(".js") or file_path.endswith(".ts") or file_path.endswith(".svelte") or file_path.endswith(".rs")
is_docs = file_path.endswith(".md") or file_path.endswith(".mdx")
return is_code or is_docs
def is_likely_useful_file(file_path):
"""Determine if the file is likely to be useful by excluding certain directories and specific file types."""
excluded_dirs = ["tests", "test", "__pycache__", "node_modules", ".venv"]
#excluded_dirs += ["docs", "examples", "benchmarks", ]
#excluded_dirs += ["scripts", "utils", ]
excluded_dirs += ["cache", ]
utility_or_config_files = ["hubconf.py", "setup.py", "package-lock.json"]
github_workflow_or_docs = ["stale.py", "gen-card-", "write_model_card"]
if any(part.startswith('.') for part in file_path.split('/')):
return False
if 'test' in file_path.lower():
return False
for excluded_dir in excluded_dirs:
if f"/{excluded_dir}/" in file_path or file_path.startswith(f"{excluded_dir}/"):
return False
for file_name in utility_or_config_files:
if file_name in file_path:
return False
return all(doc_file not in file_path for doc_file in github_workflow_or_docs)
def is_test_file(file_content):
"""Determine if the file content suggests it is a test file."""
test_indicators = ["import unittest", "import pytest", "from unittest", "from pytest"]
return any(indicator in file_content for indicator in test_indicators)
def has_sufficient_content(file_content, min_line_count=10):
"""Check if the file has a minimum number of substantive lines."""
lines = [line for line in file_content.split('\n') if line.strip() and not line.strip().startswith('#')]
return len(lines) >= min_line_count
def remove_comments_and_docstrings(source):
"""Remove comments and docstrings from the Python source code."""
tree = ast.parse(source)
for node in ast.walk(tree):
if isinstance(node, (ast.FunctionDef, ast.ClassDef, ast.AsyncFunctionDef)) and ast.get_docstring(node):
node.body = node.body[1:] # Remove docstring
elif isinstance(node, ast.Expr) and isinstance(node.value, ast.Str):
node.value.s = "" # Remove comments
return ast.unparse(tree)
def download_repo(repo_url, output_file):
"""Download and process files from a GitHub repository."""
if '/tree/' in repo_url:
repo_url = f'https://download-directory.github.io/?{repo_url}'
response = requests.get(f"{repo_url}/archive/master.zip")
zip_file = zipfile.ZipFile(io.BytesIO(response.content))
with open(output_file, "w", encoding="utf-8") as outfile:
for file_path in zip_file.namelist():
# Skip directories, non-Python files, less likely useful files, hidden directories, and test files
if file_path.endswith("/") or not is_desired_file(file_path) or not is_likely_useful_file(file_path):
continue
file_content = zip_file.read(file_path).decode("utf-8")
# Skip test files based on content and files with insufficient substantive content
if is_test_file(file_content) or not has_sufficient_content(file_content):
continue
try:
file_content = remove_comments_and_docstrings(file_content)
except SyntaxError:
# Skip files with syntax errors
continue
outfile.write(f"# File: {file_path}\n")
outfile.write(file_content)
outfile.write("\n\n")
def list_dir_recursive(directory):
files, dirs=[], []
for entry in sorted(os.listdir(directory)):
full_path = os.path.join(directory, entry)
if os.path.isdir(full_path):
dirs.append(full_path) # Do directories after files
else:
files.append(full_path)
for dir in dirs:
files += list_dir_recursive(dir)
return files
def extract_from_folder(folder, output_file):
"""Process files from given folder."""
with open(output_file, "w", encoding="utf-8") as outfile:
for file_path in list_dir_recursive(folder):
# Skip directories, non-Python files, less likely useful files, hidden directories, and test files
if file_path.endswith("/") or not is_desired_file(file_path) or not is_likely_useful_file(file_path):
print(f"Reject undesirable : {file_path}")
continue
with open(file_path, 'rt', encoding='utf-8') as f:
file_content = f.read()
# Skip test files based on content and files with insufficient substantive content
#if is_desired_file(file_content) or not has_sufficient_content(file_content):
if is_test_file(file_content):
print(f"Reject Test file : {file_path}")
continue
if not has_sufficient_content(file_content):
print(f"MAYBE Insufficient content : {file_path}")
#continue
try:
#file_content = remove_comments_and_docstrings(file_content)
pass # Actually like the commented code...
except SyntaxError:
# Skip files with syntax errors
continue
outfile.write(f"\n# --- File: {file_path} ---\n\n")
outfile.write(file_content)
outfile.write("\n\n")
print(f"Combined source code saved to {output_file}")
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python code-and-docs-from-folder.py <folder>")
sys.exit(1)
folder = sys.argv[1]
output_file = f"{folder}_code.txt"
#download_repo(repo_url, output_file)
# git clone https://github.com/stanfordnlp/dspy.git
# Prompt for 'hello world' DSPy code generation :
"""
Making use of the dspy repo code shown above,
create a simple dspy demonstration in python
that allows one to input the name of a country,
and get back the name of the capital city
(this is a very simple task, using almost none of the special features,
but will serve as a 'hello world' example for the framework)
"""
if False:
print(list_dir_recursive(folder))
if False:
for file_path in list_dir_recursive(folder):
if is_desired_file(file_path) and is_likely_useful_file(file_path):
print(file_path)
if True:
extract_from_folder(folder, output_file)
Conclusions
While many instinctively declared the long context feature of Gemini 1.5 to be a ‘RAG Killer’, it seems unlikely that this was ever a realistic outcome.
That being said, the long context is a game-changer for both existing business processes and reasoning over code.
Of course, the degree to which these capabilities have a real-world impact will depend on the pricing - since if a huge context query costs $1.00 per call, the scope for usage will be much more limited than at a price point of (say) $0.10 per call.
After-word
It has just been announced that Gemini 1.5 Pro is general release (i.e. everyone outside of Canada, the EU and UK) within AI studio, and API access is being made available on a waitlist basis.