- Published on
Images+LLMs : Advances in Multimodal Models
- Authors

- Name
- Martin Andrews
- @_mdda_
Presentation Link
Sam Witteveen and I started the Machine Learning Singapore Group (or MLSG for short) on MeetUp in February 2017 (it was previously named “TensorFlow and Deep Learning Singapore”), and the forty-third MeetUp was our sixth ‘in-person’ event since the COVID era.
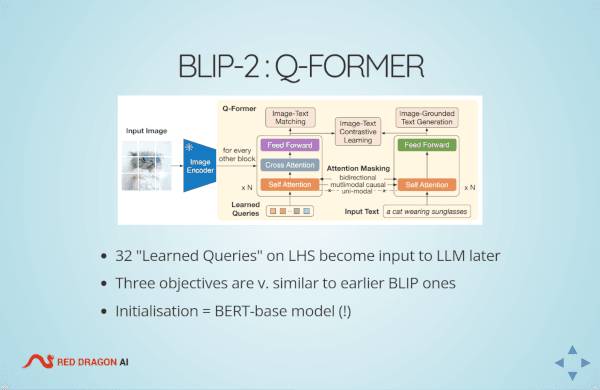
My talk covered the research fundamentals for MultiModal models, from ViT & CLIP, to InstructBLIP, via the previous BLP modals from Salesforce Singapore. I was also able to squeeze in BLIP-Diffusion.
Sam talked about HuggingFace Transformer ‘Agents’ and a comparable implementation in langchain.
Many thanks to the Google team, who not only allowed us to use Google’s Developer Space, and put out the extra chairs required for our larger-than-expected attendence, but were also kind enough to provide Pizza for the attendees!
The slides for my talk, which contain links to all of the reference materials and sources, are here :

If there are any questions about the presentation please ask below, or contact me using the details given on the slides themselves.