- Published on
Getting to Aha (notes)
- Authors

- Name
- Martin Andrews
- @_mdda_
Getting to Aha with TPUs
VertexAI Sprint (February-2025)
As part of my participation in Google’s GDE program (I have been a Google Developer Expert for AI/ML since 2017), I am given the chance to take part in various “ML Sprints” - in which we are expected to propose interesting tasks to do (using a specific technology), and then complete them. The result could be presentation materials, videos, code contributions, etc.
My idea for the VertexAI sprint was to look at whether an “Aha for low $” could be acheived using TPUs (since the free tier of TPU v3-8 available via Kaggle is very attractive, if it could be harnessed).
While significant progress was made (including a meaningful Pull-Request for the nnx gemma library) and a well-received talk was given (at the Feb-2025 MLSG MeetUp), the actual aha-demo-using-TPUs has not be realised.
Getting to Aha Using TPUs
Prior to the start of the 2-week sprint, I gathered up ideas & links into my “Getting to Aha with TPUs” repo. I have been ‘building in public’ since the start of the sprint, though my (overlong) dive into nnx produced little in the way of progress.
nnx phase
Notably, the nnx example of gemma usage in the documentation did not work, for reasons that I uncovered (after exhausting testing), and submitted a PR to solve.
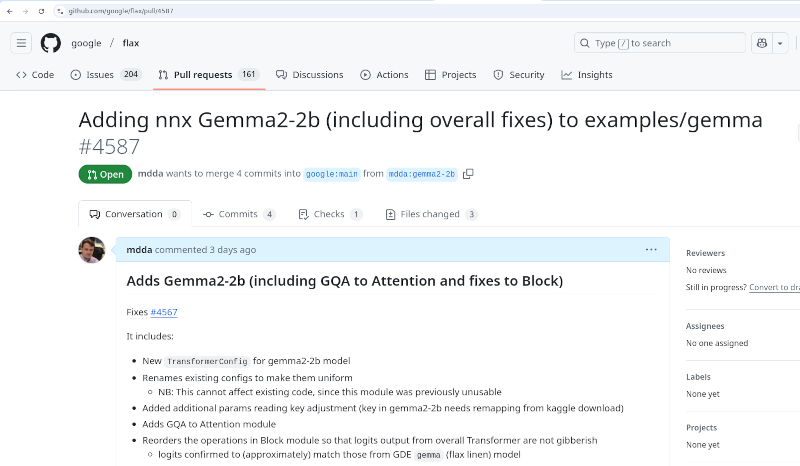
Along with my initial issue, I emailed the Googler championing nnx. Sadly, however, I have had no responses either to my Flax Issue, my email, nor the PR I submitted.
Google DeepMind gemma phase
While investing most of my time into nnx, I also checked out the gemma original library (after responding positively to their launch tweet).
Fortunately, this library worked as advertised. Indeed, it was by running parallel queries using the GDM gemma library and the nnx gemma code that I discovered that the latter was completely broken. Eventually, I found the cause of the discrepancy, which lead to the PR above.
However, the training side (along with LoRA and distribution code) of GDM gemma relies heavily on kauldron (a utilities library which, while they suggest consists of composable parts, seems to encourage a ‘build the configuration block’ style of interaction) - which goes against the spirit of making the demo code readable and hackable. This aspect was also one of my frustrations with the (pytorch) demos that had already been publicised : They involved mostly setting up a large call to a framework that hid all the interesting details and decisions.
Vertex / GCP Observations
I typically use a simple GCP n1-standard-8 instance with a T4 attached for day-to-day experiments. It beats using Colab in terms of :
- stability of the software stack
- higher amount of RAM
- ability to run processes of my choosing
- ability to leave the machine idle (not ideal, of course, but if I’m paying, I don’t need to be hassled by Colab about this)
- difficult-to-beat cost
During the sprint, I was able to make use of the GCP ability to connect the persistent disk associated with this instance to different VMs. I wanted to test out the identical environment with >100Gb RAM (to see whether more RAM would cure the nnx.jit crashes - or whether it was just a run-away process). To do this I simply shut down the existing VM, edited the VM machine type to n1-highmem-16 (which has 104Gb RAM), then restarted the VM and ran the code. Once these experiments had finished, I could easily flip back to my regular settings with just a few clicks. Since there was no compelling need to automate this kind of one-off)adjustment, the ‘console’ GUI was enough - even though my preference is to use the gcloud CLI for most tasks.
All-in-all a +1 for GCP.
Next Steps…
Even though this current sprint is now closed, I will be continuing to press forwards (though likely at lower intensity, since a lot of my initial enthusiasm has dissipated, for reasons described above).
- To get to a good TPU demo, I will likely try out the
kerasversion next:- Even though PyTorch would ordinarily be my preference, the XLA distribution code makes it look much less inviting
- The independently provided examples suggest
kerasmight work (i.e. it is more tested thannnx) - For more details about the library choice going forwards, please see the “Getting to Aha with TPUs” Repo - which is updated ‘live’
- Of course, there are still many GRPO issues to deal with …
- … and this was meant to be the focus in the first place (sad-angry-face)
As always : So many things to do, so little time!
Acknowledgements
Many thanks to Google for supporting the GCP usage for this project, which was part of their February 2025 #VertexAISprint. My contribution there was titled: “Getting to Aha on TPUs”. I also used Colab extensively for testing : Many thanks to the Colab team!