- Published on
Voices In, Voices Out - ASR, TTS
- Authors

- Name
- Martin Andrews
- @_mdda_
Presentation Link
Sam Witteveen and I started the Machine Learning Singapore Group (or MLSG for short) on MeetUp in February 2017 (it was previously named “TensorFlow and Deep Learning Singapore”), and the thirty-ninth MeetUp was our second ‘in-person’ event since the COVID era.
The MeetUp was just before the Chinese New Year, and so we recognised that not everyone who wanted to could attend - but, OTOH, we wanted to get back into a monthly rhythm this year, and delaying until after CNY would immediately throw that off.
Many thanks to the Google team, who not only allowed us to use Google’s Developer Space, but were also kind enough to provide Pizza for the attendees!
This month’s event was on the topic “Voices In, Voices Out - ASR, TTS and How Voice AI is Becoming Accessible”, and included three talks:
- New Frontiers in TTS - Martin Andrews :
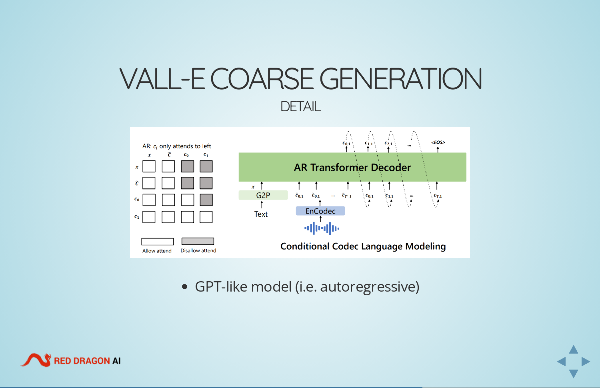
- Microsoft’s VALL-E is a new entrant in the race to getting TTS systems across the uncanny valley. Martin briefly outlined how TTS systems in the past have been constructed, and then explained how the newest transformer-based systems (including Google’s AudioLM) are tackling the problem by including unsupervised learning.
- OpenAI’s Whisper and adding to it for a production ASR system. - Sam Witteveen
- OpenAI’s Whisper model has been out for a few months now and has proven to be a winner for cheap high quality ASR. Sam talked about how the model works, additions that can be made such as speaker diarization, generating accurate time stamps serving the model in a production app.
- Riffusion lightning talk - Rishabh Anand
- Stable Diffusion has taken the world by storm, making it easier to generate images (now, video!) through text. What if you could do the same for audio? By first formulating audio generation as image generation and then “decoding” this audio image, Riffusion pieces together an audio sample representative of the text prompts simply through finetuning. Rishabh briefly explained how Stable Diffusion is repurposed for audio generation, and the different settings in which you can use Riffusion off the shelf.
The slides for my talk, which contain links to all of the reference materials and sources, are here :

If there are any questions about the presentation please ask below, or contact me using the details given on the slides themselves.