- Published on
Learning to Think, Not Learning to Solve
- Authors

- Name
- Martin Andrews
- @_mdda_
A Recurring Pattern
Instruction Fine-Tuning
Instruction Fine-Tuning (IFT) was originally framed as teaching a model to answer questions. The FLAN paper1 showed that training on around 1,800 different question topics was “enough” for the model to generalise to a much broader range of questions.
So, one might argue that given a broad enough range of questions, the model learns to generalise around the kind of questions that are asked.
On the other hand, IFT can also be re-framed as a meta-learning task: the key wasn’t that the model learned to answer questions better - the key was that the model learned that questions ought to be answered. This is a meta-skill - generalising out of the example sets of Q&A tasks provided. The “Less Is More for Alignment” paper2 reinforces this interpretation, showing that as few as 1,000 carefully curated examples could achieve strong results. The diversity of topics wasn’t teaching content - it was teaching the inclination to answer question (a generalisable skill).
Reinforcement Learning from Human Feedback (RLHF)
Early RLHF work focused on case-by-case preference learning: show the model which responses are better in a specific situation, then in a different situation, and so on. The meta-learning interpretation - that the real goal was getting the model to internalise helpfulness and harmlessness as important qualities in responses, rather than learning how to respond in many situations - was something the community arrived at gradually rather than understanding from the outset.
Constitutional AI3 is an example of explicitly designing for the meta-goal: instead of labelling thousands of preference pairs, articulate the principles and let the model learn from those.
RL for Reasoning (Right Now)
The current focus on RL environments for reasoning suggests a repeat of the same pattern. Qwen 3.54, for example, showed improvements as the number of training environments expanded. The implicit assumption: cover enough tasks, hope to generalise locally around those tasks, and eventually encompass enough human reasoning activity.
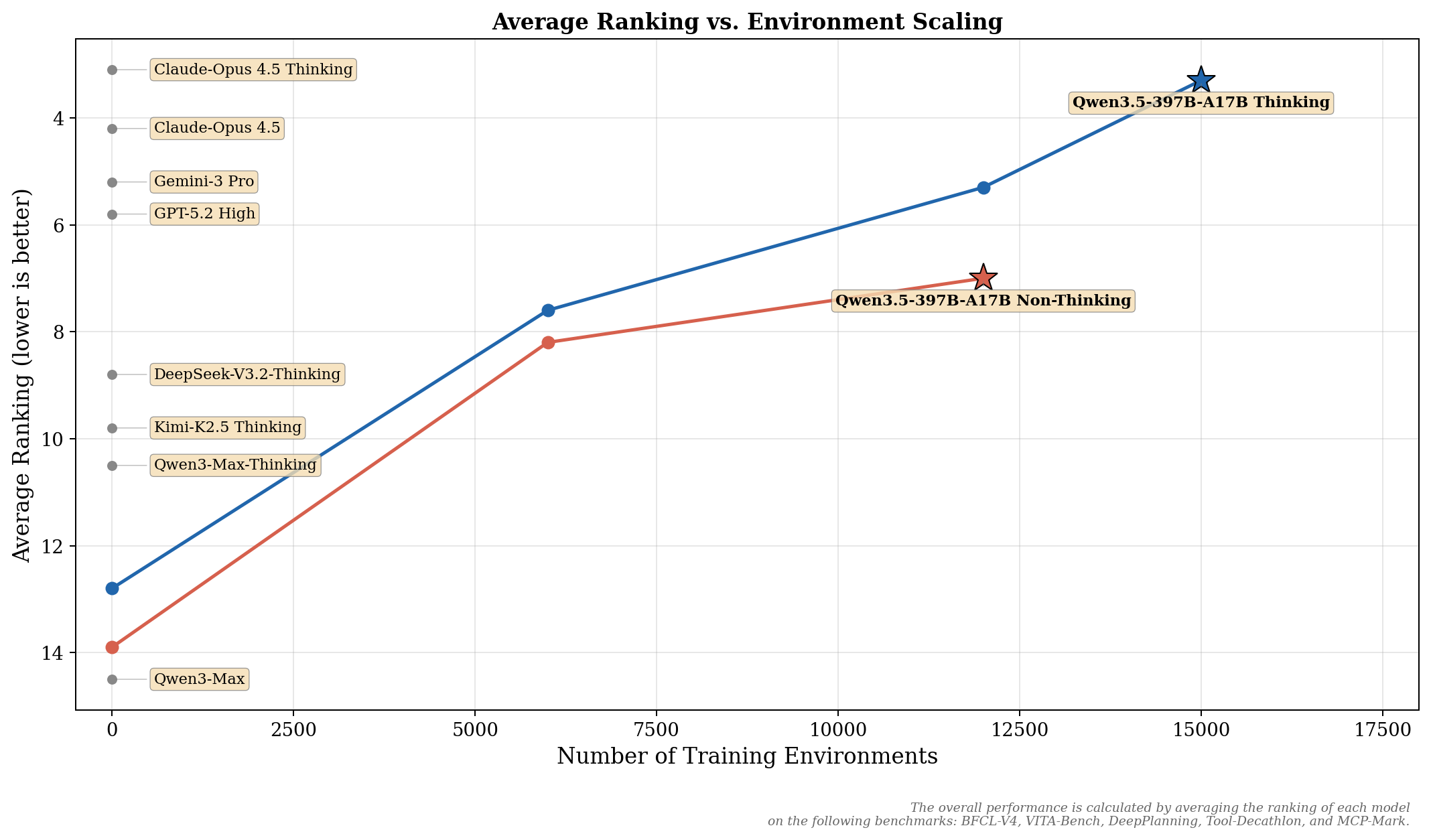
This perspective was reiterated in a recent Dario Amodei (Anthropic CEO) interview5, where he specifically emphasised that after the pretraining phase (where human data is the key factor), the number of environments available (for the machine to create its own data) was an important area of scaling.
So to the extent that we are building these RL environments, the goal is very similar to what was done five or ten years ago with pre-training. We’re trying to get a whole bunch of data, not because we want to cover a specific document or a specific skill, but because we want to generalize.
Perhaps we should reframe RL environments not as a way to cover so many tasks that we learn to generalise as a by-product, but as a means of creating a meta-learning task: training the model to want to reason and explore on its own - to develop the mental meta-tools required for self-direction.
How do we shift the RL-for-reasoning goal from “get good at math/code/specific domains” to “develop the habit of thinking carefully”?
The Environments Are the Curriculum, Not the Objective
We don’t teach kids algebra primarily so they can solve equations - we teach them algebra so they develop structured reasoning. The equations are the curriculum: The thinking is the objective.
If RL environments are the curriculum rather than the objective, then their sequencing and selection matters enormously. There’s a parallel to curriculum learning in education - you don’t teach calculus before arithmetic. This raises an open research question: What’s the right progression of RL environments to induce meta-cognitive development rather than domain-specific skill?
This framing also speaks to a widely observed problem: the RL generalisation gap. Current reasoning models are strong in trained domains but brittle outside them. That brittleness is evidence that current RL is doing case-by-case learning rather than successfully teaching the meta-disposition. If we were teaching models to think, they’d transfer. The fact that they don’t suggests we’re still teaching them to solve.
Is there a way to quantify this gap?
Is “Wanting to Reason” a Token-Level Idea?
Learning token-by-token is a beautifully parallelisable training method - in the pretraining and SFT cases, it maps well onto GPU hardware. But it may be putting blinders on what we can teach, because the “thinking” between the tokens has to be learned from too.
For straightforward question answering, the context likely suggests the correct answer in the sense of being a probabilistic map. When genuine reasoning is required, though, we’re asking the model to perform a process it has rarely directly observed. It may be difficult for the model to “understand” that it’s not the reasoning tokens themselves that are valuable, but that the process of reasoning creates useful context for itself.
The current RL from Verifiable Rewards (RLVR) paradigm provides a low amount of feedback on whether contexts actually became valuable - i.e., whether the final answer was correct. That’s a weak way to incentivise the actual skill we’re looking for. It’s like grading a student only on final answers and never looking at their working: You’ll sometimes reward those who got lucky and penalise those who reasoned well but made an arithmetic slip.
Note that RL has already abandoned the speed-up inherent in fully parallel training - the RLVR process involves multiple serial token-wise rollouts. This means we could, in principle, incorporate richer signals that aren’t available during standard transformer training. (There’s a later companion post explores this in detail.)
What Would “Mental Meta-Tools” Look Like?
If we want to teach models to think rather than to solve, we should try to be specific about what “thinking” consists of. Here’s a sketch of the meta-tools a reasoning model would need:
Decomposition
Decomposition - breaking problems into manageable sub-problems - seems like a core human reasoning strategy6.
Problem-solving might be decomposed into a set of “atomic” thinking strategies. You can get an LLM to categorise thinking styles in reasoning rollouts and cluster them - Google’s Self-Discover work7 takes this approach. If such a taxonomy exists, could we implement a LoRA-like or activation-overlay method, applying suitable “thinking vectors” over the next “thinking chunk” dynamically?
This raises the question of who selects which vector to apply. If it’s the model itself, we’ve pushed the meta-learning problem up one level. This connects to the next set of meta-tools - and perhaps the the strategy-switching model, the self-prompting teacher, and the thinking-vector selector could all be facets of the same meta-controller.
Strategy Switching: Knowing When to Explore vs. Exploit
As a mathematician, certain instincts become second nature:
- Recognising when an elegant re-thinking step has just occurred — something “just clicked”
- Sensing that the current solution is becoming too messy to lead anywhere interesting
- Intuiting that there’s something ready to be found, just out of reach
- Feeling that some new kind of thinking is required
These instincts are born of experience and a sense of taste. How can they be trained for? Models typically witness tokens that display good behaviours in papers and teaching materials, but “paths not taken” are only ever implicit. The decision to switch strategies - which may be the most important reasoning skill - is almost never directly supervised.
One training idea: separately model the chunk-to-chunk idea transitions, creating a dictionary of “ideas” to be inserted between chunks to make each following chunk more likely. This could enable a “strategy switching model” that takes as input the current chunk’s representations or statistics and decides what kind of thinking should come next.
A related thought: models could be trained to fill in gaps with extra discrete tokens that make the next token more likely. Pure likelihood maximisation may be over-eager here - one could also imagine a loss that maximised “just being the winning next token” rather than maximising the full probability.
Self-Monitoring
People don’t just reason linearly - they run sanity checks, intentionally increase diversity in their solution paths, and redirect attention toward approaches that seem promising. This resembles an internal reward model, one that might be trained to be internally self-hoisting.
Ideally, a model could serve as its own reward model, since multi-goal feedback can often cross-pollinate: the features needed for self-evaluation (recognising coherence, spotting errors, assessing progress) are likely useful for reasoning itself.
Self-Prompting
Currently, most efforts to get models to prompt themselves (e.g., GEPA via DSPy8) amount to “cross your fingers and then see how well the new prompt works” - there’s little reason to expect models to know how to prompt themselves effectively without training for it.
A more principled approach: train a Teacher model to prompt a Student toward better reasoning, where rewards reflect the student’s uplift in correctness and certainty (for example, see Sakana AI’s “Reinforcement Learning Teachers of Test Time Scaling”9). If the Teacher could then be integrated with the Student - or is the Student, or uses some kind of rolling-average approach like DINO10 - the model could prompt itself to encourage better reasoning.
One way to think about it: effective reasoning is like laying track in your own context - each step you write down creates the rails that carry you toward the answer. Self-prompting is learning to lay that track deliberately.
Understanding Your Own State of Mind
The model should be able to assess its own internal process:
- Knowing what it doesn’t know, and calibrating confidence accordingly
- Recognising when a problem is outside its competence
- Detecting when its current reasoning chain is based on shaky premises
- Sensing when multiple valid approaches exist and it shouldn’t commit prematurely
Not all uncertainty is the same - is this a knowledge gap, an underspecified problem, or a reasoning step the model can’t verify? Different types of uncertainty call for different responses.
The training challenge is that RLVR actively discourages this kind of self-awareness. A model that says “I’m uncertain” gets no reward, while a model that confidently guesses sometimes gets lucky. Financial markets have a parallel problem, and cope with it through risk management - discouraging risky bets, rewarding well-calibrated uncertainty. We could design analogous reward structures that perhap reward models that express doubt on questions they’d otherwise get wrong across multiple rollouts.
This connects to the power of consensus in RL rollouts. Over many rollouts, bad reasoning scatters across many different answers, while good reasoning converges to one11. A model with good self-understanding / calibration would essentially internalise the information that consensus-across-rollouts provides externally - knowing, from the inside, what currently requires rollout diversity to discover from the outside.
Evaluation
How would we evaluate whether a model has acquired these meta-skills, versus just getting better at specific tasks? Without a measurement framework, the thesis around the value of meta-skill learning risks being unfalsifiable.
A “meta-skill benchmark” might test transfer of reasoning strategies to domains that are structurally dissimilar to training domains but still require the meta-tools described above - decomposition, strategy-switching, self-monitoring, epistemic calibration. If a model trained on mathematical reasoning via RL can then reason well about experimental design or legal analysis, that’s evidence of meta-learning. If it can’t, we’re still in case-by-case territory.
One complication: in current token-level evaluations, people guard against overlap between train and test sets. But models learn a tower of representations across (for example) 96 different layers - testing for contamination at the representation level is a much harder challenge. And yet we know that simply renaming variables in programming tasks can throw models off, suggesting they remain very overfit at the token level. A model that has genuinely learned to think should be robust to such surface-level changes.
Conclusion
The history of this field suggests a testable prediction: just as IFT needed far fewer examples than expected once it was teaching the idea of question answering rather than covering topics, and just as Constitutional AI could replace thousands of preference labels with a handful of principles, there should exist a small, well-chosen set of RL environments that induces genuine meta-cognitive ability - and that set should transfer to domains it has never seen.
The most decisive experiment would be something like this: train reasoning via RL on a deliberately narrow set of environments chosen for diversity of required thinking strategies rather than domain coverage. Then test on entirely novel domains. If the meta-learning framing is correct, this should outperform training on a much larger set of environments chosen for domain breadth. If it doesn’t, the current trajectory of expanding environment coverage is the right approach.
Video related to this post

This is the first of two posts. The second, “Signals Between the Tokens”, explores concrete architectural and training mechanisms that could support these meta-cognitive capabilities.
Footnotes
Wei et al, 2021 : “Finetuned Language Models Are Zero-Shot Learners” ↩
Zhou et al, 2023 : “LIMA: Less Is More for Alignment” ↩
Bai et al, 2022 : “Constitutional AI: Harmlessness from AI Feedback” ↩
Dario Amodei - (“We are near the end of the exponential”)[https://www.youtube.com/watch?v=n1E9IZfvGMA] interview with Dwarkesh Patel ↩
(aside: perhaps this is also what limits human thinking to problems with a manageable chunk-size.) ↩
Zhou et al, 2024 : “Self-Discover: Large Language Models Self-Compose Reasoning Structures” ↩
Agrawal et al, 2025 : “GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning” ↩
Cetin et al, 2025 : “Reinforcement Learning Teachers of Test Time Scaling” ↩
Caron et al, 2021 : “Emerging Properties in Self-Supervised Vision Transformers” ↩
Denny Zhuo presentation : “Teach Language Models to Reason” ↩